
YOLOv8 リアルタイム物体検出2(高度技術解析:Anchor-Free Object Detection / DFL / TAL)
Anchor-Free Object Detection
YOLOv8 は、従来のアンカーベースの物体検出手法からアンカーフリー(Anchor-Free)アプローチへと進化しました。この革新的な設計により、事前定義されたアンカーボックスに依存せず、特徴マップ上の各グリッドセルが直接物体の存在と位置を予測します。アンカーフリー方式は、手動でのアンカー設計が不要となり、異なるデータセットへの汎用性が大幅に向上しました。本記事では、YOLOv8 のアンカーフリー検出を支える三つの核心技術——Distribution Focal Loss (DFL) による確率分布ベースの境界ボックス回帰、Task-Aligned Assigner (TAL) を用いた動的な正負サンプル割り当て、そして改良されたDecoupled Head の構造——について詳細に解説します。これらの先進的な技術要素がどのように協調して、YOLOv8 が高精度と高速推論を両立させているかを理解することで、実務における物体検出システムの最適化とカスタマイズに大きく貢献できるでしょう。
アンカーベース手法の歴史と仕組み
アンカー(Anchor)の概念は、2015年に Microsoft が発表した Faster R-CNN で初めて導入されました。それ以前の物体検出アルゴリズムは、スライディングウィンドウや Selective Search などの方法で候補領域を生成しており、計算コストが高く効率的ではありませんでした。Faster R-CNN の RPN(Region Proposal Network)は、アンカーメカニズムを導入することで、物体のサイズやアスペクト比の変化に対応する画期的な解决方案を提供しました。
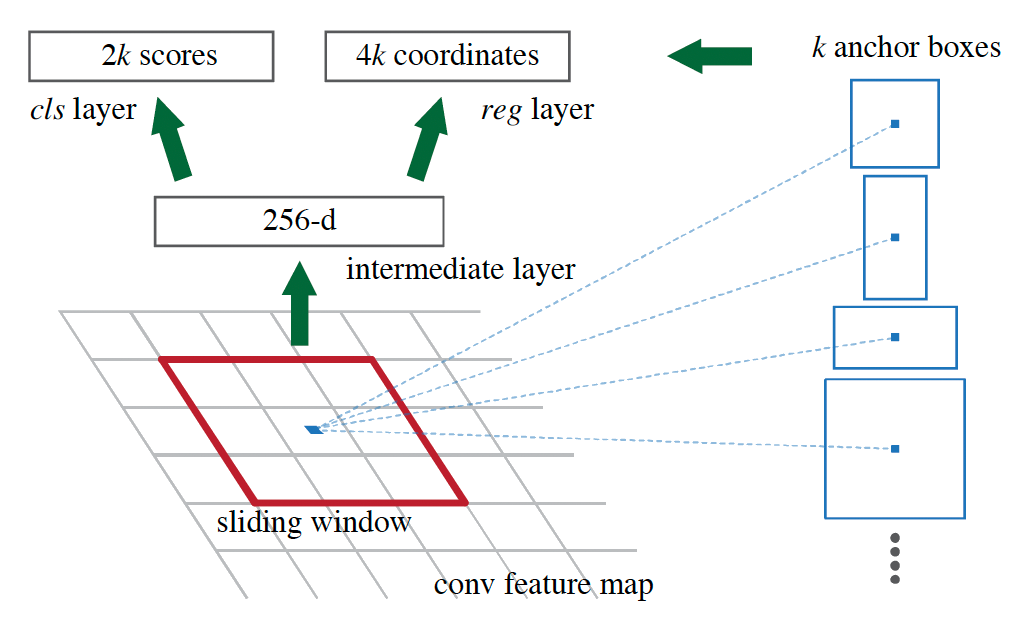
アンカーベース手法の特徴
アンカーベース手法では、特徴マップの各ピクセル位置に、異なるサイズとアスペクト比を持つ複数のアンカーボックスを事前に設定します。例えば、3つのスケール(小・中・大)× 3つのアスペクト比(1:1, 1:2, 2:1)= 9つのアンカーを各位置に配置します。訓練过程中、各アンカーと正解ボックス(GT: Ground Truth)との IoU(Intersection over Union)を計算し、閾値に基づいて正样本・负样本を判定します。
アンカーと GT ボックスの重要な違い:
- 生成方法:アンカーはモデルが事前定義または学習过程中に使用する参照枠であり、GT ボックスは人間が手動でアノテーションした実際の物体境界です。
- 座標系:アンカーは特徴マップ上の位置に基づいて定義され、GT ボックスは画像のピクセル座標系で定義されます(両者はストライド倍率で対応付けられます)。
- 役割:アンカーは「候補」として機能し、GT との比較を通じて正负样本として分類され、回帰目標となります。
クラシックなアンカーベース手法:
- Two-stage: Faster R-CNN(2015)
- One-stage: SSD(2015)、RetinaNet(2017)
アンカーフリー手法の革新
アンカーフリー(Anchor-Free)手法は、事前定義されたアンカーボックスを使用しないアプローチです。「アンカーがない」のではなく、「先験的なアンカー設計が不要」という意味で、特徴マップ上の各点を直接アンカー点として扱い、その点からの相対オフセットやキーポイントを検出して物体を検出します。
アンカーフリーの主な利点
-
ハイパーパラメータ削減:
- アンカーのサイズ、アスペクト比、数量などを手動で設計する必要がありません
- データセット固有のチューニング作業が大幅に軽減されます
-
汎用性向上:
- 異なるデータセットやドメイン間でモデルを転移させる際、アンカー再設計が不要
- 特殊な形状やサイズの物体にも柔軟に対応可能
-
計算効率:
- 多数のアンカーボックスとの IoU 計算が不要
- メモリ使用量と計算コストが削減されます
-
シンプルさ:
- モデルアーキテクチャが簡素化
- 実装とデバッグが容易になります
アンカーフリー手法の分類
アンカーフリー手法は主に2つのアプローチに大別されます:
1. キーポイントベース(Keypoint-based)
- CornerNet(2018):物体の左上隅と右下隅の2つのキーポイントを検出し、ペアリングしてバウンディングボックスを構成
- CenterNet(2019):物体の中心点と幅・高さを直接予測
2. 中心点ベース(Center-based)
- YOLOv1(2015):実は初期の YOLO もアンカーフリーの概念を持っていました。各グリッドセルが物体の中心を含む場合、直接ボックスを予測
- FCOS(2019):Fully Convolutional One-Stage Object Detection。各ピクセルから物体の4辺までの距離を直接回帰
- YOLOX(2021):YOLO シリーズで初めて公式にアンカーフリーを採用
YOLOv8 におけるアンカーフリーの実装
YOLOv8 は YOLOX のアンカーフリーアプローチを継承・改良し、さらに高度な技術を統合しています:
訓練時の処理フロー:
- バックボーンとネックを通じて、3つのスケールの特徴マップを出力(例:80×80、40×40、20×20)
- 各特徴マップ上の各点が1つのアンカー点(予測点)として機能
- Task-Aligned Assigner (TAL) により、各アンカー点を正样本・负样本に動的に割り当て
- DFL を用いて、各正样本からバウンディングボックスの4辺までの相対オフセットを確率分布として予測
- 分類スコアと位置オフセットの損失を計算し、バックプロパゲーションで更新
推論時の処理フロー:
- 各アンカー点で分類スコアとボックスオフセットを予測
- DFL モジュールにより、確率分布から連続的なオフセット値を復元
- アンカー点座標とオフセットから絶対座標のバウンディングボックスを計算
- NMS(Non-Maximum Suppression)で重複検出を除去
- 最終的な検出結果を出力
このアンカーフリー設計により、YOLOv8 は複雑なアンカーチューニングなしで、多様な物体検出タスクに高い性能を発揮できます。
Distribution Focal Loss (DFL)
YOLOv8 の境界ボックス回帰において、従来の Dirac delta 分布に基づく直接的な座標予測ではなく、Distribution Focal Loss (DFL) を採用しています。この手法は Generalized Focal Loss (GFL) の一部として提案され、境界ボックスの位置をより柔軟かつ正確に表現することを可能にしました。
背景:従来の境界ボックス表現の問題点
従来の物体検出モデルでは、境界ボックスの座標を Dirac delta 分布 として扱っていました。これは、各座標値を単一の確定値として予測するアプローチです。しかし、この方法には以下の問題点がありました:
-
不確実性の考慮不足:実際の画像では、物体の境界が曖昧な場合や、アノテーションに不確実性が存在する場合が多くあります。Dirac delta 分布はこのような複雑な状況に対応できません。
-
表現の硬直性:単一の確定値のみを予測するため、モデルが境界ボックス位置の背後にある確率分布を学習することができません。
-
ガウス分布の限界:一部の研究ではガウス分布を導入しましたが、これも対称性を前提とした単純化であり、実際の複雑な分布を捉えるには不十分でした。
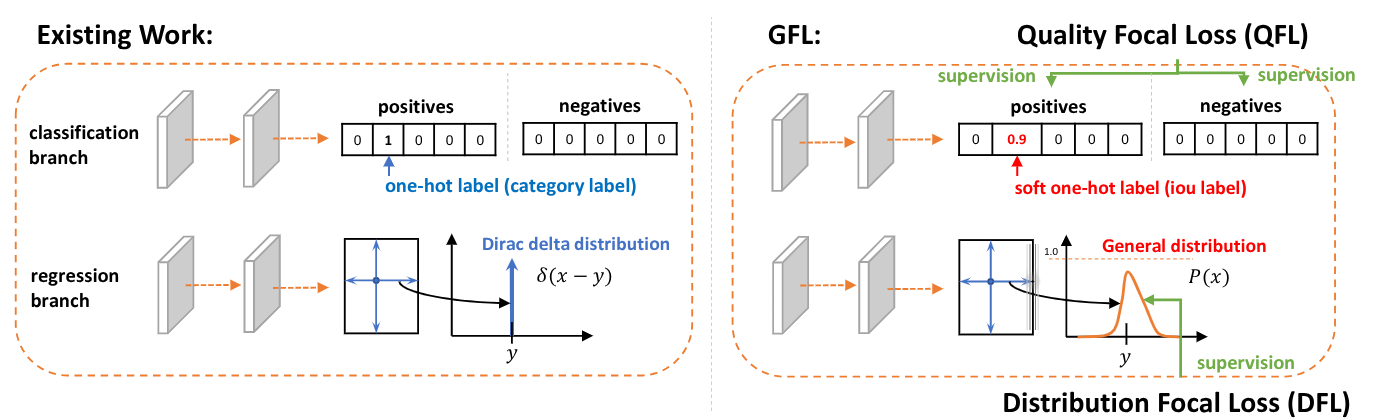
Distribution Focal Loss (DFL) は、アンカー点から境界ボックスの四辺までの相対オフセットを回帰目標として採用し、単一オフセットを一般分布(General Distribution)で表現します。
DFL の核心思想:一般分布の学習
DFL は、境界ボックスの座標値を 離散確率分布 として表現します。具体的には:
1. 連続空間の離散化
境界ボックスのオフセット値 $ y $ の範囲 $ [y_0, y_n] $ を、等間隔 $ \Delta = 1 $ で離散化した集合 $ {y_0, y_1, …, y_i, y_{i+1}, …, y_{n-1}, y_n} $ に変換します。
YOLOv8 では reg_max = 16 を使用しているため、オフセットの取り得る値は {0, 1, 2, …, 14, 15} の16個の整数となります。
2. 確率分布の予測
モデルは、オフセット値が各整数点に落在する確率 $ P(y_i) $ を予測します。すべての確率の合計は 1 になります:
この確率分布 $ P(x) $ は、$ n+1 $ 個のノードを持つ softmax 層 で実現されます。
3. 期待値としての最終予測値
予測された確率分布から、オフセットの最終的な推定値 $ \hat{y} $ は、確率加重平均(期待値)として計算されます:
これにより、モデルは連続的なオフセット値を、離散確率分布の期待値として表現できます。
Distribution Focal Loss の数式
DFL の損失関数は、予測された確率分布が真のオフセット値 $ y $ の周辺に集中するように設計されています。最も近い2つの整数点 $ y_i \leq y \leq y_{i+1} $ を選び、以下の損失を最小化します:
ここで:
- $ S_i $ と $ S_{i+1} $ は、それぞれ $ y_i $ と $ y_{i+1} $ に対する予測確率(softmax 出力)
- $ y_{i+1} - y $ と $ y - y_i $ は、重み係数(距離に反比例)
この損失関数の特徴:
- 線形補間:真の値 $ y $ に近い整数点ほど高い確率を持つように誘導
- 焦点効果:正解に近い分布形状を促進し、学習効率を向上
- 微分可能性:端到端での最適化が可能
YOLOv8 における DFL の実装
コード例:DFL モジュール
# ultralytics/nn/modules/head.py から抜粋
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Distribution Focal Loss で使用される積分モジュール。
確率分布から期待値を計算し、連続的な境界ボックス座標を取得します。
Proposed in "Generalized Focal Loss" https://arxiv.org/abs/2006.04388
"""
def __init__(self, c1=16):
"""
Initialize a convolutional layer with a given number of input channels.
Args:
c1 (int): 入力チャンネル数(reg_max)。デフォルトは16。
"""
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
# 0 から reg_max-1 までの整数リストを作成
# 例:reg_max=16 なら [0, 1, 2, ..., 15]
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""
Applies convolution to input tensor and returns transformed tensor.
Args:
x (torch.Tensor): 入力テンソル shape(B, 4*reg_max, N)
B: バッチサイズ
4*reg_max: 4方向×reg_max チャンネル
N: アンカー点数
Returns:
(torch.Tensor): 出力テンソル shape(B, 4, N)
各方向の期待値(連続的なオフセット値)
"""
# 形状変更: (B, 4*reg_max, N) → (B, 4, reg_max, N)
b, c, a = x.shape
x = x.view(b, 4, self.c1, a)
# softmax を適用して確率分布に変換
x = x.softmax(2)
# 畳み込み演算で期待値を計算
# conv の重みは [0, 1, 2, ..., reg_max-1]
# 結果: (B, 4, 1, N) → (B, 4, N)
x = self.conv(x)
x = x.view(b, 4, a)
return x
DFL の使用フロー
# 訓練時の DFL 処理フロー
# 1. Detect Head の出力
# pred_dist: (B, 4*reg_max, H, W) - 境界ボックスの確率分布
# 例: (B, 64, 80, 80) for reg_max=16
# 2. 次元の再構成
pred_dist = pred_dist.view(B, 4, reg_max, -1) # (B, 4, 16, 8400)
# 3. Softmax で確率分布に変換
prob_dist = pred_dist.softmax(dim=2) # (B, 4, 16, 8400)
# 4. DFL モジュールで期待値を計算
# 重み [0, 1, 2, ..., 15] との畳み込み
distances = dfl_module(prob_dist) # (B, 4, 8400)
# 5. Anchor points から境界ボックス座標へ変換
# distances: (left, top, right, bottom) の相対オフセット
bboxes = dist2bbox(distances, anchor_points) # (B, 4, 8400)
損失計算における DFL
DFL の損失計算は、予測された確率分布が正解オフセット値の周辺に集中するように設計されています。このプロセスは以下のステップで構成されます:
DFL損失の数式的理解
DFL損失の核心は、連続的な目標値 に対して、最も近い2つの離散点 と の確率を最適化することです:
この式の意味:
- 線形補間:目標値 が に近いほど、 の確率を高くするよう誘導
- 重み付きクロスエントロピー:距離に応じた重みで2つの項を組み合わせ
- 勾配の流れ: と の両方に勾配が流れ、効率的な学習が可能
コード詳細解説
DFL 損失計算の各ステップを詳しく見ていきましょう:
Step 1: GTボックスから相対オフセットへ変換
# 目標ボックスを相対オフセット(分布表現)に変換
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
この処理により、絶対座標の GT ボックス [x1, y1, x2, y2] が、アンカー点からの相対オフセット [left, top, right, bottom] に変換されます。例えば:
- アンカー点:
(cx, cy) = (10, 10) - GT ボックス:
(x1, y1, x2, y2) = (5, 6, 15, 18) - 相対オフセット:
(left, top, right, bottom) = (5, 4, 5, 8)
Step 2: 正样本の抽出
# 前景マスクで正样本のみを抽出
pred_dist_fg = pred_dist[fg_mask] # shape: N_pos * 4, reg_max+1
target_ltrb_fg = target_ltrb[fg_mask] # shape: N_pos * 4
TAL (Task-Aligned Assigner) によって割り当てられた正样本のみを対象にします。负样本は DFL 損失の計算に含まれません。
Step 3: 形状変更と平坦化
# 4方向のオフセットを全て同じ次元に平坦化
pred_dist_flat = pred_dist_fg.view(-1, self.reg_max + 1) # shape: N_pos*4, 17
target_flat = target_ltrb_fg.view(-1) # shape: N_pos*4
左・上・右・下の4方向のオフセットを全て同じバッチ次元にまとめます。これにより、一度に全てのオフセット方向で損失を計算できます。
Step 4: floor と ceil の取得
# 目標値のfloorとceilを取得
tl = target.long() # y_i (例: target=5.7 なら tl=5)
tr = tl + 1 # y_{i+1} (例: tr=6)
連続的な目標値 に対して、最も近い2つの整数点を取得します。これは DFL の離散化表現に対応しています。
Step 5: 重み計算(線形補間係数)
# 重みを計算(線形補間の係数)
wl = tr - target # y_{i+1} - y (例: 6 - 5.7 = 0.3)
wr = 1 - wl # y - y_i (例: 5.7 - 5 = 0.7)
目標値がどちらの整数点に近いかに応じて重みを計算します:
- が に近い → が大きくなる → の確率をより重視
- が に近い → が大きくなる → の確率をより重視
Step 6: 重み付きクロスエントロピー損失
# クロスエントロピー損失に重みを掛けて加算
loss_left = F.cross_entropy(pred_dist_flat, tl.view(-1), reduction="none") * wl
loss_right = F.cross_entropy(pred_dist_flat, tr.view(-1), reduction="none") * wr
loss_dfl_per_element = loss_left + loss_right
ここで重要なポイント:
F.cross_entropyは softmax + negative log likelihood を計算- 2つの整数点に対する損失を、距離に応じた重みで組み合わせ
- これにより、確率分布が目標値の周辺に集中するよう誘導
Step 7: 平均化と形状復元
# 4方向の平均を取って形状を復元
loss_dfl = loss_dfl_per_element.view(tl.shape).mean(-1, keepdim=True)
各アンカー点の4方向(左・上・右・下)の損失を平均し、元の形状に戻します。
Step 8: 重み付けと正規化
# 分類スコアに基づく重み付け
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
loss_dfl_weighted = loss_dfl * weight
# バッチ全体で正規化
loss_dfl_final = loss_dfl_weighted.sum() / target_scores_sum
- 重み付け: 分類スコアの高い正样本ほど、位置回帰の損失も重要視
- 正規化: バッチサイズや正样本数による損失の変動を抑える
具体的な計算例
例として、あるアンカー点での右方向オフセットの DFL 損失計算を示します:
設定:
reg_max = 16(離散化点数)- 目標オフセット:
- 予測された確率分布:
計算過程:
- ,
- ,
この損失を最小化することで、モデルは と の確率を適切に調整し、期待値が 5.7 に近づくように学習します。
DFL損失の特徴
DFL 損失には以下のような重要な特徴があります:
-
連続ラベルの扱い:
- 従来のクロスエントロピー損失は離散ラベル {0, 1} しか扱えません
- DFL は連続的なオフセット値 を直接最適化可能
- 線形補間により、滑らかな勾配の流れを実現
-
分布形状の誘導:
- 目標値の近くの整数点に確率質量を集中させるよう誘導
- 単峰性の分布を自然に学習(追加の制約なし)
- 不確実性の大きい場合、分散の大きい分布も表現可能
-
計算効率:
- 単純なクロスエントロピー計算のみ使用
- 追加の複雑な演算不要
- GPU 上で効率的に並列計算可能
-
正样本のみで学習:
- 负样本は DFL 損失に含まれない
- 明確な位置情報を持つ正样本のみで回帰を学習
- 背景領域での不安定な学習を回避
-
タスクアライメント:
- 分類スコアに基づく重み付け
- 高信頼度の検出ほど、位置精度も重視
- 分類と位置回帰の一貫性を促進
# ultralytics/utils/loss.py から抜粋
class BboxLoss(nn.Module):
"""
訓練中の損失計算のための境界ボックス損失クラス。
IoU 損失と DFL 損失の両方を計算します。
"""
def __init__(self, reg_max, use_dfl=False):
"""
BboxLoss モジュールを初期化します。
Args:
reg_max (int): DFL の最大値(通常15)
use_dfl (bool): DFL 損失を使用するかどうか
"""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points,
target_bboxes, target_scores, target_scores_sum, fg_mask):
"""
境界ボックス損失を計算します。
Args:
pred_dist (Tensor): 予測された分布 shape(B*N, 4, reg_max+1)
pred_bboxes (Tensor): デコードされた予測ボックス shape(B*N, 4)
anchor_points (Tensor): アンカー点座標
target_bboxes (Tensor): 目標ボックス shape(B*N, 4)
target_scores (Tensor): 目標スコア
target_scores_sum (float): 目標スコアの合計
fg_mask (Tensor): 前景マスク(正样本)
Returns:
loss_iou (Tensor): IoU 損失
loss_dfl (Tensor): DFL 損失
"""
# IoU 損失の計算
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask],
xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL 損失の計算
if self.use_dfl:
# 目標ボックスを相対オフセット(分布表現)に変換
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
# DFL 損失を計算
loss_dfl = self._df_loss(
pred_dist[fg_mask].view(-1, self.reg_max + 1),
target_ltrb[fg_mask]
) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
@staticmethod
def _df_loss(pred_dist, target):
"""
左側と右側の DFL 損失の合計を返します。
Distribution Focal Loss (DFL) は "Generalized Focal Loss" で提案されました。
https://ieeexplore.ieee.org/document/9792391
Args:
pred_dist (Tensor): shape(bs * num_total_anchors * 4, reg_max + 1)
予測された確率分布
target (Tensor): shape(bs * num_total_anchors * 4,)
目標オフセット値(連続値)
Returns:
(Tensor): DFL 損失値
"""
# 目標値のfloorとceilを取得
tl = target.long() # target left (y_i) - DFL公式の y_i
tr = tl + 1 # target right (y_{i+1}) - DFL公式の y_{i+1}
# 重みを計算(線形補間の係数)
wl = tr - target # weight left - DFL公式の (y_{i+1} - y)
wr = 1 - wl # weight right - DFL公式の (y - y_i)
# クロスエントロピー損失に重みを掛けて加算
# log(P_i) * wl + log(P_{i+1}) * wr
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none")
.view(tl.shape) * wl # 左側の項
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none")
.view(tl.shape) * wr # 右側の項
).mean(-1, keepdim=True)
DFL の利点
DFL の主な利点は、柔軟な分布表現、高精度な回帰、効率的な学習、そしてエンドツーエンド最適化の4点に集約されます。まず、Dirac delta やガウス分布のような制限された仮定を必要とせず、任意の形状の確率分布を学習可能であるため、物体境界の不確実性を自然に表現できます。次に、確率分布の期待値として連続値を予測し、周辺の値の確率も考慮するため、より頑健な予測が可能となり、特に曖昧な境界を持つ物体に対して効果的です。さらに、正解値の近傍に確率質量を集中させるよう誘導することで収束速度が向上し、追加の計算オーバーヘッドは最小限に抑えられます。最後に、微分可能な操作のみで構成されているため、既存の検出パイプラインにシームレスに統合でき、追加の推論コストなしで性能を向上させることができます。
座標変換の補助関数
YOLOv8 では、境界ボックス座標と相対オフセット(分布表現)の間の変換を行うためのユーティリティ関数が提供されています:
bbox2dist: バウンディングボックスから相対オフセットへ
この関数は、絶対座標のバウンディングボックス(xyxy形式)を、アンカー点からの相対オフセット(ltrb形式)に変換します。DFL の学習のために使用されます。
# ultralytics/utils/tal.py から抜粋
def bbox2dist(anchor_points, bbox, reg_max):
"""
バウンディングボックス(xyxy形式)を相対オフセット(ltrb形式)に変換します。
Args:
anchor_points (Tensor): アンカー点の座標 shape(N, 2)
例: 8x5 の特徴マップの場合、
[[0,0],[1,0],...,[7,0],
[0,1],[1,1],...,[7,1],
...]
bbox (Tensor): バウンディングボックス shape(N, 4) xyxy形式
reg_max (int): DFL の最大値(通常16)
Returns:
(Tensor): 相対オフセット shape(N, 4) - 左、上、右、下の順
値は [0, reg_max - 0.01] の範囲にクリップ
"""
# ボックスを左上(x1,y1)と右下(x2,y2)に分割
x1y1, x2y2 = bbox.chunk(2, -1)
# 各方向の相対オフセットを計算
# 左: anchor_x - x1, 上: anchor_y - y1
# 右: x2 - anchor_x, 下: y2 - anchor_y
dist = torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1)
# 有効な範囲にクリップ
dist = dist.clamp_(0, reg_max - 0.01)
return dist
処理の流れ:
- 入力分割: バウンディングボックス
[x1, y1, x2, y2]を左上[x1, y1]と右下[x2, y2]に分割 - オフセット計算: アンカー点からの相対距離を4方向で計算
- 左:
anchor_x - x1(アンカーから左端までの距離) - 上:
anchor_y - y1(アンカーから上端までの距離) - 右:
x2 - anchor_x(右端からアンカーまでの距離) - 下:
y2 - anchor_y(下端からアンカーまでの距離)
- 左:
- 結合: 4つのオフセットを連結して
[left, top, right, bottom]形式に - クリッピング: DFL の離散化範囲内に収めるため、
[0, reg_max - 0.01]に制限
dist2bbox: 相対オフセットからバウンディングボックスへ
この関数は、DFL が予測した相対オフセット(ltrb形式)を、実際のバウンディングボックス座標(xywh または xyxy形式)に変換します。推論時に使用されます。
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""
相対オフセット(ltrb形式)をバウンディングボックス(xywhまたはxyxy形式)に変換します。
Args:
distance (Tensor): 相対オフセット shape(N, 4) - ltrb順
anchor_points (Tensor): アンカー点座標 shape(N, 2)
xywh (bool): Trueならxywh形式、Falseならxyxy形式で出力
dim (int): 分割する次元
Returns:
(Tensor): バウンディングボックス座標
"""
# オフセットを左上(lt)と右下(rb)に分割
lt, rb = distance.chunk(2, dim)
# 絶対座標を計算
x1y1 = anchor_points - lt # 左上座標
x2y2 = anchor_points + rb # 右下座標
if xywh:
# 中心座標と幅・高さに変換
c_xy = (x1y1 + x2y2) / 2 # 中心座標
wh = x2y2 - x1y1 # 幅と高さ
return torch.cat((c_xy, wh), dim) # xywh 形式
else:
# xyxy 形式で返す
return torch.cat((x1y1, x2y2), dim)
処理の流れ:
- 入力分割: 相対オフセット
[left, top, right, bottom]を左上[left, top]と右下[right, bottom]に分割 - 絶対座標計算: アンカー点とオフセットから実際の座標を復元
- 左上:
x1y1 = anchor_points - lt(アンカーから左/上にオフセット分戻る) - 右下:
x2y2 = anchor_points + rb(アンカーから右/下にオフセット分進む)
- 左上:
- 形式変換(条件分岐):
- xywh=True: 中心座標と幅・高さに変換
- 中心:
c_xy = (x1y1 + x2y2) / 2 - 幅高さ:
wh = x2y2 - x1y1 - 出力:
[center_x, center_y, width, height]
- 中心:
- xywh=False: そのまま xyxy 形式で出力
- 出力:
[x1, y1, x2, y2]
- 出力:
- xywh=True: 中心座標と幅・高さに変換
両関数の関係:
bbox2dist: 訓練時に使用(GTボックス → 相対オフセット → DFL学習)dist2bbox: 推論時に使用(DFL予測 → 相対オフセット → 最終ボックス)- 互いに逆変換の関係にあります
アンカー点の生成
DFL を使用するためには、特徴マップ上の各位置に対応するアンカー点(グリッド中心)を生成する必要があります:
make_anchors: アンカー点の生成
この関数は、複数スケールの特徴マップから、各グリッドセルの中心座標(アンカー点)を生成します。
# ultralytics/utils/tal.py から抜粋
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""
特徴マップからアンカー点を生成します。
Args:
feats (List[Tensor]): 複数スケールの特徴マップリスト
Detect タスクの場合、Detect モジュールの出力
各要素のshape: (N, reg_max*4+nc, H, W)
strides (List[int]): 各スケールのストライド値
例: [8, 16, 32]
grid_cell_offset (float): グリッドセル内のオフセット値
デフォルトは0.5(セル中心)
Returns:
anchor_points (Tensor): 全スケールのアンカー点座標 shape(total_anchors, 2)
stride_tensor (Tensor): 各アンカー点に対応するストライド shape(total_anchors, 1)
"""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device
# 各スケールの特徴マップに対してアンカー点を生成
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
# x, y 方向の座標を生成(オフセット付き)
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset
# メッシュグリッドを作成
sy, sx = torch.meshgrid(sy, sx, indexing="ij")
# 座標をスタックして平坦化
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
# ストライドテンソルを作成
stride_tensor.append(torch.full((h * w, 1), stride,
dtype=dtype, device=device))
# 全スケールのアンカー点を結合
return torch.cat(anchor_points), torch.cat(stride_tensor)
検出ヘッド(Detect Header)
YOLOv8 の検出ヘッドは、アンカーフリー方式を採用しており、事前に定義されたアンカーボックスに依存せず、直接物体の中心座標と幅・高さを予測します。この設計思想は、物体の形やサイズに依存しない汎用的な物体検出が可能になりました。
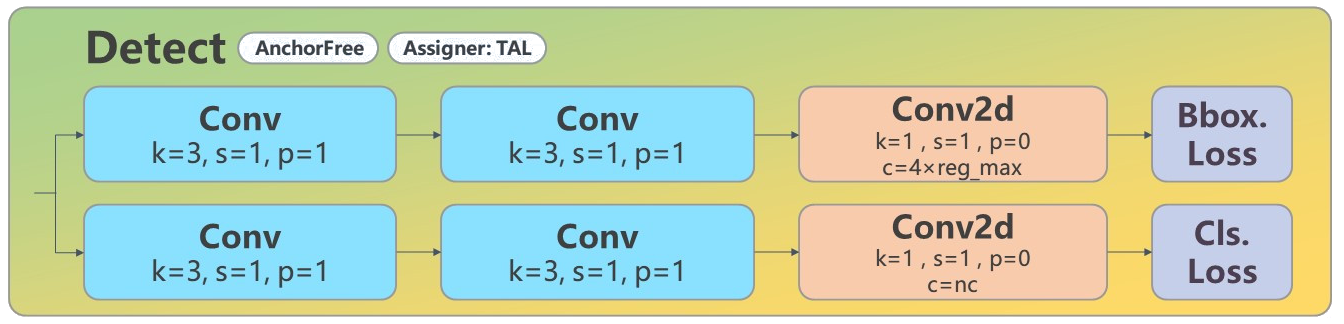
Detect Head の基本構造
YOLOv8 の検出タスクの本質は、特徴マップの各グリッドセル(grid cell)上で、対応する バウンディングボックス(bbox:4つの分布回帰パラメータ)+ 分類(class logits) を予測することです。
YOLOv8 では、境界ボックス回帰に DFL(Distribution Focal Loss) を導入しており、これにより Head の出力次元が従来の xywh 直接回帰とは異なります。
検出ヘッドの出力形式(DFL 表現)
各予測点において:
-
4つの境界ボックス座標 → 各座標を reg_max=16 の離散分布で表現
-
つまり、各座標は16個の確率を予測するため、合計 4×16 = 64 チャンネル
-
类别予測チャンネル数 = nc(例:COCO データセットでは 80)
したがって、Head の出力チャンネル数は:
no = 4 * reg_max + nc = 64 + 80 = 144
Detect Head の構造(マルチブランチ畳み込み)
YOLOv8 のコードにおける実装:
📍 ファイル:ultralytics/nn/modules/head.py
📍 クラス:class Detect(nn.Module)
class Detect(nn.Module):
"""
YOLOv8 の検出層を初期化します。
指定されたクラス数とチャンネル数に基づいて、検出ヘッドを構築します。
Args:
nc (int): クラス数(例:COCOなら80)
ch (tuple): バックボーンの特徴マップからのチャンネルサイズのタプル
"""
dynamic = False # グリッド再構成を強制
export = False # エクスポートモード
format = None # エクスポート形式
end2end = False # エンドツーエンド
max_det = 300 # 最大検出数
shape = None
anchors = torch.empty(0) # 初期化
strides = torch.empty(0) # 初期化
legacy = False # v3/v5/v8/v9 モデルとの後方互換性
xyxy = False # xyxy または xywh 出力
def __init__(self, nc: int = 80, ch: Tuple = ()):
super().__init__()
self.nc = nc # クラス数
self.nl = len(ch) # 検出層の数(通常3層:P3, P4, P5)
self.reg_max = 16 # DFL チャンネル数(ch[0] // 16 に比例)
self.no = nc + self.reg_max * 4 # 各アンカーあたりの出力数
self.stride = torch.zeros(self.nl) # ビルド時に計算されるストライド
# チャンネル数の計算
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100))
# バウンディングボックス回帰ブランチ(cv2)
# 各スケールの特徴マップに対して、3層の畳み込みを実行
# 最終的に 4 * reg_max = 64 チャンネルを出力
self.cv2 = nn.ModuleList(
nn.Sequential(
Conv(x, c2, 3), # 3x3 畳み込み
Conv(c2, c2, 3), # 3x3 畳み込み
nn.Conv2d(c2, 4 * self.reg_max, 1) # 1x1 畳み込みで64チャンネル出力
) for x in ch
)
# 分類ブランチ(cv3)
# Legacy モードと通常モードで構造が異なる
# 通常モードでは Depthwise Convolution を使用して効率化
self.cv3 = (
nn.ModuleList(
nn.Sequential(
Conv(x, c3, 3),
Conv(c3, c3, 3),
nn.Conv2d(c3, self.nc, 1)
) for x in ch
)
if self.legacy
else nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)), # DWConv + 1x1 Conv
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)), # DWConv + 1x1 Conv
nn.Conv2d(c3, self.nc, 1), # 最終的な分類出力
)
for x in ch
)
)
# Distribution Focal Loss のための DFL モジュール
# reg_max > 1 の場合のみ有効
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
# エンドツーエンド推論用のコピー(オプション)
if self.end2end:
self.one2one_cv2 = copy.deepcopy(self.cv2)
self.one2one_cv3 = copy.deepcopy(self.cv3)
バウンディングボックス回帰ブランチ(cv2)
# bbox 回帰ブランチ
# 各スケールの特徴マップからバウンディングボックスのパラメータを予測
# 出力:4 * reg_max = 64 チャンネル(DFL 表現)
self.cv2 = nn.ModuleList(
nn.Sequential(
Conv(x, c2, 3), # 第1層:3x3 畳み込み
Conv(c2, c2, 3), # 第2層:3x3 畳み込み
nn.Conv2d(c2, 4 * self.reg_max, 1) # 第3層:1x1 畳み込みで64チャンネル出力
) for x in ch # ch は各スケールの入力チャンネル数
)
分類ブランチ(cv3)
# 分類ブランチ
# 各スケールの特徴マップからクラス確率を予測
# 出力:nc チャンネル(クラス数)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(
DWConv(x, x, 3), # Depthwise 畳み込み(効率的な特徴抽出)
Conv(x, c3, 1) # 1x1 畳み込み
),
nn.Sequential(
DWConv(c3, c3, 3), # Depthwise 畳み込み
Conv(c3, c3, 1) # 1x1 畳み込み
),
nn.Conv2d(c3, self.nc, 1) # 最終的な分類出力(nc チャンネル)
) for x in ch
)
forward メソッドの動作(訓練時)
Detect の forward メソッドは以下の2つの主要な処理を行います:
-
各スケールで box と cls を結合:
# 各スケールの特徴マップに対して、bboxブランチとclsブランチの出力をチャンネル方向で結合 # 例:[B, 64, H, W] + [B, 80, H, W] → [B, 144, H, W] for i in range(self.nl): x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) -
訓練状態ではデコードせずに直接返す:
# 訓練時は生の出力を返す(損失計算のため) # 推論時のみデコード処理を実行 if self.training: return x
例えば、640×640 の画像を入力とした場合、FPN は3層の特徴マップを出力します:
| 層 | 特徴マップサイズ | 出力 shape(B=1 の場合) |
|---|---|---|
| P3 | 80×80 | [1, 144, 80, 80] |
| P4 | 40×40 | [1, 144, 40, 40] |
| P5 | 20×20 | [1, 144, 20, 20] |
総予測点数:
80×80 + 40×40 + 20×20 = 6400 + 1600 + 400 = 8400 点
つまり、YOLOv8 は1枚の画像から 8400 個の予測点 を生成し、各点で144次元の出力(64次元のbbox + 80次元の分類)を行います。
TAL (Task-Aligned Assigner)
YOLOv8 の正負样本割り当てには、Task-Aligned Assigner (TAL) が採用されています。これは TOOD (Task-aligned One-stage Object Detection) で提案された手法で、分類タスクと位置回帰タスクの最適アンカー点が一致するように設計されています。
背景:タスク不对齐の問題
従来の単一ステージ検出器では、分類と位置回帰を2つの並列ブランチで独立して実行するため、以下の問題が発生していました:
1. 分類と位置回帰の独立性
2つの独立したブランチ設計により、タスク間の相互作用が欠如し、予測時に不整合が生じます。例えば、あるアンカー点が高い分類スコアを持つ一方で、別のアンカー点がより正確な境界ボックスを予測するといった状況が発生します。
2. タスク非依存の样本割り当て
- アンカーフリー検出器:幾何学的な基準(物体中心に近いアンカー点)を使用
- アンカーベース検出器:IoU の閾値に基づいて割り当て
しかし、分類と位置回帰の最適アンカー点は必ずしも一致せず、物体の形状や特徴によって大きく変化する可能性があります。これにより、NMS 処理中に正確な境界ボックスが不正確なものに抑制されるリスクがあります。
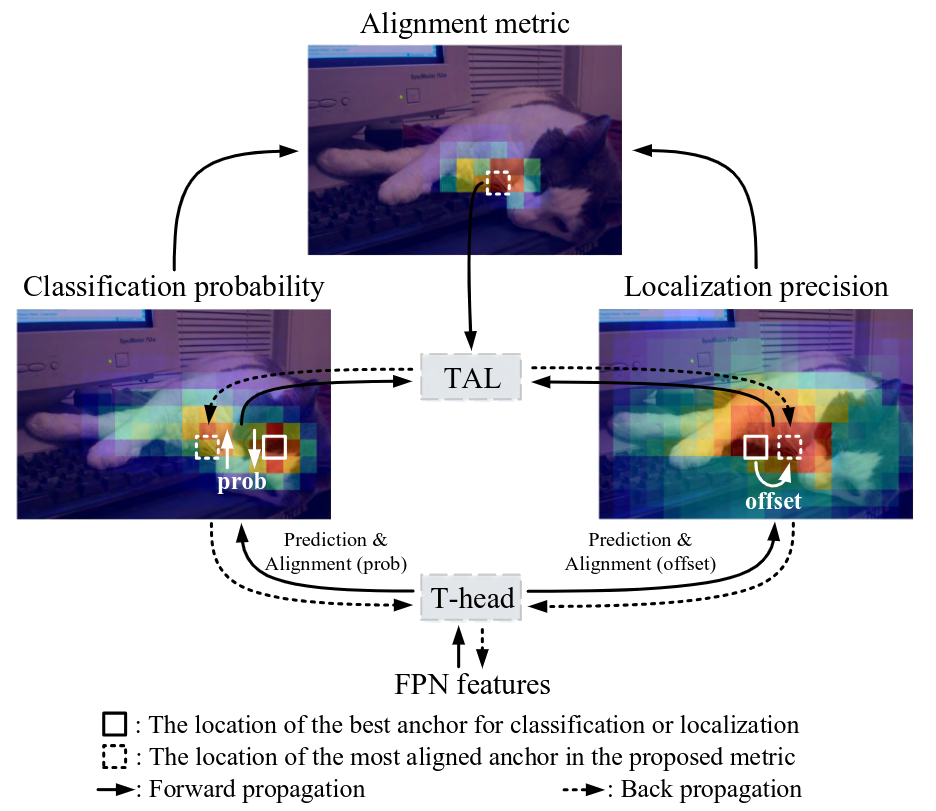
Task-Aligned Head (T-Head)
TOOD では、従来の並列ヘッド構造を改良した Task-Aligned Head (T-Head) を提案しました。
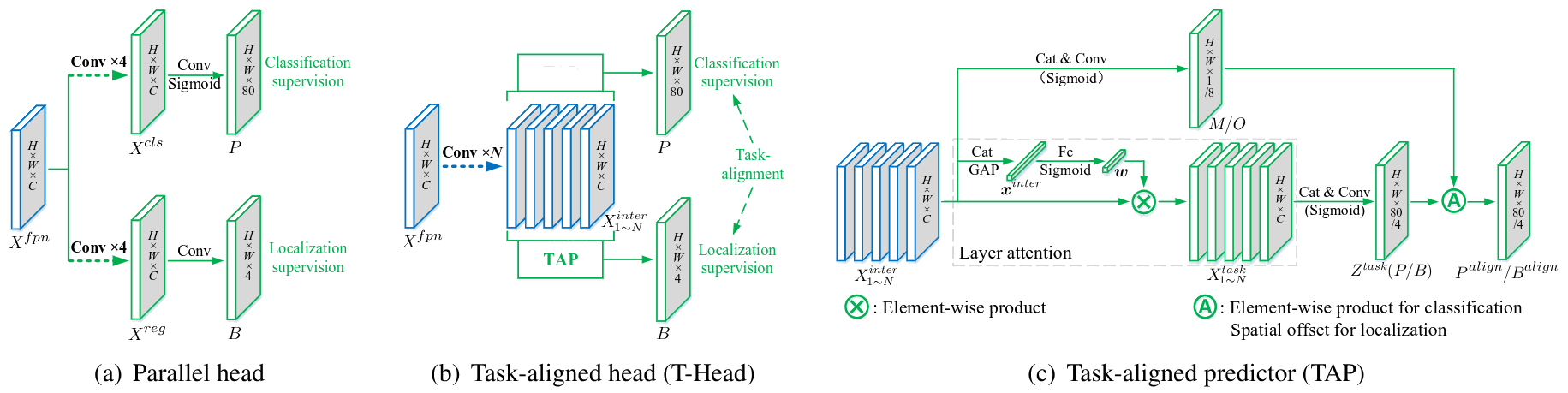
従来の並列ヘッドの問題点
- 2つのブランチが完全に独立
- タスク間の相互作用なし
- 特徴の空間分布が異なる可能性
T-Head の革新
T-Head は以下の3つの主要コンポーネントで構成されます:
1. タスク交互特徴抽出器
複数の畳み込み層を通じて、分類と位置回帰の両方に有益なタスク交互特徴を学習します:
ここで、(FPN 特徴)、 は ReLU 活性化関数です。
2. レイヤー注意力機構
タスク固有の特徴を動的に計算し、タスク分解を促進します:
ここで、 は学習されたレイヤー注意力ベクトルです。
3. タスクアライメント予測器 (TAP)
-
空間確率図 M:分類予測を調整
-
空間オフセット図 O:位置予測を調整
これらのアライメント図は、交互特徴から自動的に学習されます。
Task Alignment Learning (TAL)
TAL は、T-Head に学習信号を提供し、2つのタスクの最適アンカー点を明示的に近づける(甚至統一する)ための学習戦略です。
タスクアライメント指標
TAL の核心は、分類スコアと IoU を組み合わせたタスクアライメント指標 です:
ここで:
- :分類スコア(予測されたクラスの確率)
- :IoU(予測ボックスと GT ボックスの交差比)
- :分類タスクの重み(YOLOv8 では 0.5)
- :位置回帰タスクの重み(YOLOv8 では 6.0)
指標の意味:
- が大きい → 高い分類スコア かつ 高精度な位置回帰
- が小さい → 分類または位置回帰のどちらか(または両方)が不正確
YOLOv8 での実装:
# ultralytics/utils/tal.py から抜粋
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
訓練样本分配
TAL の样本分配戦略は非常にシンプルです:
各 GT インスタンスに対して:
- 全てのアンカー点でタスクアライメント指標 を計算
- 値が最大の top-k 個のアンカー点を正样本として選択
- 残りのアンカー点を负样本として扱う
この戦略により、分類と位置回帰の両方で高品質な予測を行うアンカー点のみが正样本として使用されます。
タスクアライメント損失
TAL は、アライメント指標 を活用して損失関数を設計しています:
分類損失:
正样本のラベルを二元ラベル {0, 1} ではなく、正規化されたアライメント指標 に置き換えます:
ここで、 はインスタンスレベルで正規化され、最大値がそのインスタンスの最大 IoU 値と等しくなります。
焦点損失(Focal Loss)を適用:
位置回帰損失:
アライメント指標 で重み付けされた GIoU 損失:
ここで、 は予測ボックス、 は GT ボックスです。
総損失:
YOLOv8 における TAL の実装
YOLOv8 では、TOOD の TAL を簡略化・最適化して採用しています。
TaskAlignedAssigner のコード解説
YOLOv8 の TAL 実装は ultralytics/utils/tal.py の TaskAlignedAssigner クラスにあります。処理フローを詳しく見ていきましょう。
Step 1: GT 内のアンカー点を選択
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
"""
GT 内の正样本アンカー中心を選択します。
各 GT ボックスに対して、アンカー点がボックス内にあるかどうかを判定するマスクを生成します。
Args:
xy_centers (Tensor): shape(h*w, 2) - アンカー中心座標
gt_bboxes (Tensor): shape(b, n_boxes, 4) - GT ボックス (xyxy形式)
Returns:
(Tensor): shape(b, n_boxes, h*w) - ブール型テンソル
True: アンカー中心が対応するGT内
False: アンカー中心がGT外
"""
n_anchors = xy_centers.shape[0]
bs, n_boxes, _ = gt_bboxes.shape
# GT ボックスを左上 (lt) と右下 (rb) に分割
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # shape: (b*n_boxes, 1, 2)
# 各アンカー中心と GT の境界との距離を計算
# bbox_deltas: shape(b, n_boxes, n_anchors, 4)
# [x_center - x_left, y_center - y_top, x_right - x_center, y_bottom - y_center]
bbox_deltas = torch.cat(
(xy_centers[None] - lt, rb - xy_centers[None]),
dim=2
).view(bs, n_boxes, n_anchors, -1)
# 全ての4方向の距離が正(epsより大きい)場合、アンカーはGT内
return bbox_deltas.amin(3).gt_(eps)
処理の流れ:
- GT ボックスを左上
(x1, y1)と右下(x2, y2)に分割 - 各アンカー点
(cx, cy)に対して、4方向の距離を計算:- 左:
cx - x1(正ならアンカーは左境界より右) - 上:
cy - y1(正ならアンカーは上境界より下) - 右:
x2 - cx(正ならアンカーは右境界より左) - 下:
y2 - cy(正ならアンカーは下境界より上)
- 左:
- 4方向全てが正の場合、アンカーは GT 内と判定
Step 2: アライメント指標と IoU を計算
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
"""
予測ボックスと GT ボックスのアライメント指標と IoU を計算します。
Args:
pd_scores (Tensor): shape(bs, num_total_anchors, num_classes)
予測分類スコア
pd_bboxes (Tensor): shape(bs, num_total_anchors, 4)
予測ボックス(DFL からデコード済み)
gt_labels (Tensor): shape(bs, n_max_boxes, 1)
gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)
mask_gt (Tensor): shape(bs, n_max_boxes, h*w)
GT 内のアンカー点マスク
Returns:
align_metric (Tensor): shape(b, max_num_obj, na) - アライメント指標
overlaps (Tensor): shape(b, max_num_obj, na) - CIoU 値
"""
na = pd_bboxes.shape[-2] # num_total_anchors
mask_gt = mask_gt.bool()
# 初期化
overlaps = torch.zeros([self.bs, self.n_max_boxes, na],
dtype=pd_bboxes.dtype, device=pd_bboxes.device)
bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na],
dtype=pd_scores.dtype, device=pd_scores.device)
# インデックス作成
ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long)
ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # バッチインデックス
ind[1] = gt_labels.squeeze(-1) # クラスラベル
# 各 GT に対する予測分類スコアを取得
# pd_scores[ind[0], :, ind[1]]: 正しいクラスのスコアのみ抽出
bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt]
# 予測ボックスと GT ボックスを展開して形状を合わせる
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
# CIoU を計算
overlaps[mask_gt] = self.iou_calculation(gt_boxes, pd_boxes)
# アライメント指標を計算: t = s^α * u^β
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
return align_metric, overlaps
重要なポイント:
- 分類スコアの抽出: 各 GT の正しいクラスに対応する予測スコアのみを使用
- CIoU の使用: より正確な重なり評価のため、CIoU (Complete IoU) を採用
- アライメント指標: (YOLOv8 のデフォルト)
- が大きいため、IoU の影響が強く、位置精度の高いアンカー点を優先
Step 3: Top-k アンカー点を選択
def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
"""
指定された指標に基づいて top-k 候補を選択します。
各 GT ボックスに対して、アライメント指標が最大の top-k アンカー点を選択します。
Args:
metrics (Tensor): shape(b, max_num_obj, h*w) - アライメント指標
largest (bool): True なら最大値を選択
topk_mask (Tensor): 任意のブール型マスク
Returns:
(Tensor): shape(b, max_num_obj, h*w) - 選択された top-k マスク
"""
# top-k の指標とインデックスを取得
# shape: (b, max_num_obj, topk)
topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
if topk_mask is None:
topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)
# 無効なインデックスを 0 に設定
topk_idxs.masked_fill_(~topk_mask, 0)
# カウンターテンソルを作成して scatter_add で top-k 位置に 1 を設定
count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)
ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)
for k in range(self.topk):
# 各 k に対して、対応する位置に 1 を加算
count_tensor.scatter_add_(-1, topk_idxs[:, :, k : k + 1], ones)
# 複数の GT に割り当てられたアンカーをフィルタリング(1 より大きい場合 0 に)
count_tensor.masked_fill_(count_tensor > 1, 0)
return count_tensor.to(metrics.dtype)
処理の流れ:
torch.topkで各 GT に対してアライメント指標が最大の top-k インデックスを取得- scatter_add を使用して、選択された位置に 1 を設定
- 1つのアンカーが複数GTに選択された場合、そのアンカーを無効化(後で解決)
Step 4 & 5: マスク結合と重複解決
# Step 4: マスクを結合
mask_pos = mask_topk * mask_in_gts * mask_gt
# Step 5: 重複割り当てを解決
target_gt_idx, fg_mask, mask_pos = self.select_highest_overlaps(
mask_pos, overlaps, self.n_max_boxes
)
select_highest_overlaps の処理:
@staticmethod
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
"""
1つのアンカーが複数 GT に割り当てられた場合、IoU が最大の GT を選択します。
Args:
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
overlaps (Tensor): shape(b, n_max_boxes, h*w)
Returns:
target_gt_idx (Tensor): shape(b, h*w) - 各アンカーに割り当てられた GT インデックス
fg_mask (Tensor): shape(b, h*w) - 前景マスク
mask_pos (Tensor): shape(b, n_max_boxes, h*w) - 更新された正样本マスク
"""
# 各アンカーに割り当てられた GT の数を計算
fg_mask = mask_pos.sum(-2) # shape: (b, h*w)
if fg_mask.max() > 1: # 重複割り当てが存在
# 複数 GT に割り当てられたアンカーのマスク
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1)
# IoU が最大の GT のインデックスを取得
max_overlaps_idx = overlaps.argmax(1) # shape: (b, h*w)
# 最大 IoU の位置に 1 を設定
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
# 複数割り当ての場合、最大 IoU の GT のみ保持
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float()
fg_mask = mask_pos.sum(-2)
# 各アンカーがどの GT にサービスするか(インデックス)
target_gt_idx = mask_pos.argmax(-2) # shape: (b, h*w)
return target_gt_idx, fg_mask, mask_pos
重要なポイント:
- 重複解決: 1つのアンカーが複数GTに割り当てられた場合、IoU が最大のGTのみを選択
- これにより、各アンカーは高々1つのGTにのみ割り当てられる
Step 6 & 7: 目標値割り当てと正規化
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
正样本アンカー点に対する目標ラベル、目標ボックス、目標スコアを計算します。
Args:
gt_labels (Tensor): shape(b, max_num_obj, 1)
gt_bboxes (Tensor): shape(b, max_num_obj, 4)
target_gt_idx (Tensor): shape(b, h*w) - 割り当てられた GT インデックス
fg_mask (Tensor): shape(b, h*w) - 前景マスク
Returns:
target_labels (Tensor): shape(b, h*w) - 目標分類ラベル
target_bboxes (Tensor): shape(b, h*w, 4) - 目標ボックス
target_scores (Tensor): shape(b, h*w, num_classes) - 目標スコア
"""
# バッチインデックスを作成
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # 平坦化インデックス
# 目標ラベルを割り当て
target_labels = gt_labels.long().flatten()[target_gt_idx] # shape: (b, h*w)
# 目標ボックスを割り当て
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx] # shape: (b, h*w, 4)
# 目標スコア(One-hot)を作成
target_labels.clamp_(0)
target_scores = torch.zeros(
(target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device,
) # shape: (b, h*w, 80)
# scatter_ で One-hot エンコーディング
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
# 负样本のスコアを 0 に設定
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
正規化処理:
# アライメント指標を正規化
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # 各GTの最大アライメント指標
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # 各GTの最大IoU
# 正規化されたアライメント指標
norm_align_metric = (
align_metric * pos_overlaps / (pos_align_metrics + self.eps)
).amax(-2).unsqueeze(-1)
# 目標スコアに重み付け
target_scores = target_scores * norm_align_metric
正規化の意味:
- 高品質な正样本(高いアライメント指標と IoU)ほど、目標スコアが大きくなる
- これにより、モデルは高品質なサンプルからより多く学ぶ
- 困難なサンプル(低いアライメント指標)の影響
関連資料
- YOLOv8 リアルタイム物体検出1 (基礎) - YOLOv8 architecture and basic concepts
- YOLOv8 リアルタイム物体検出3(損失関数の詳細解説) - 損失関数の完全な実装と理論解説